阿里 Qwen3 深夜炸场!8 款模型 + 混合推理王炸组合
2025 年4月29日凌晨4点,阿里云通义千问扔下一枚 “开源核弹”——Qwen3 系列模型震撼上线!2小时内GitHub星标狂飙 16.9k,刷新大模型开源速度纪录。
继斯坦福HAI报告中6款模型入选全球关注榜后,阿里再次用技术硬实力证明:中国开源大模型,正在改写全球 AI 格局!
一个模型两种大脑,毫秒级响应 + 深度推理随意切换从小手机到大企业,全场景刚需一次满足
Qwen3 首创 “人类级思考引擎”,自带两种模式一键切换,彻底终结 “速度与精度” 的两难选择:
Qwen3 这次直接甩出“模型矩阵”王炸,8款模型覆盖0.6B到235B参数规模,堪称“AI 界瑞士军刀”:
6 款稠密模型玩出 “参数魔法”
0.6B 小模型能跑手机端,4B 模型性能追平上一代 72B,参数效率暴增 18 倍;8B 以上支持 128K 超长上下文,轻松 Hold 住万字合同。
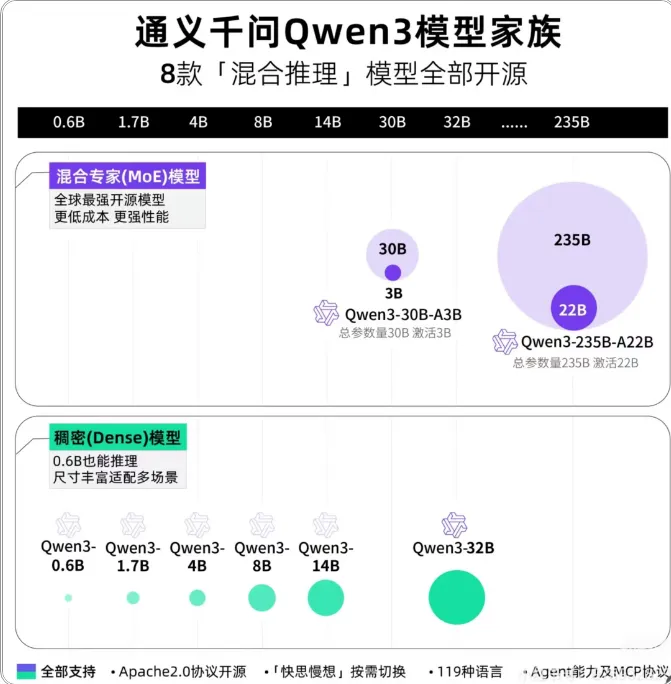
2款 MoE 模型刷新性价比天花板
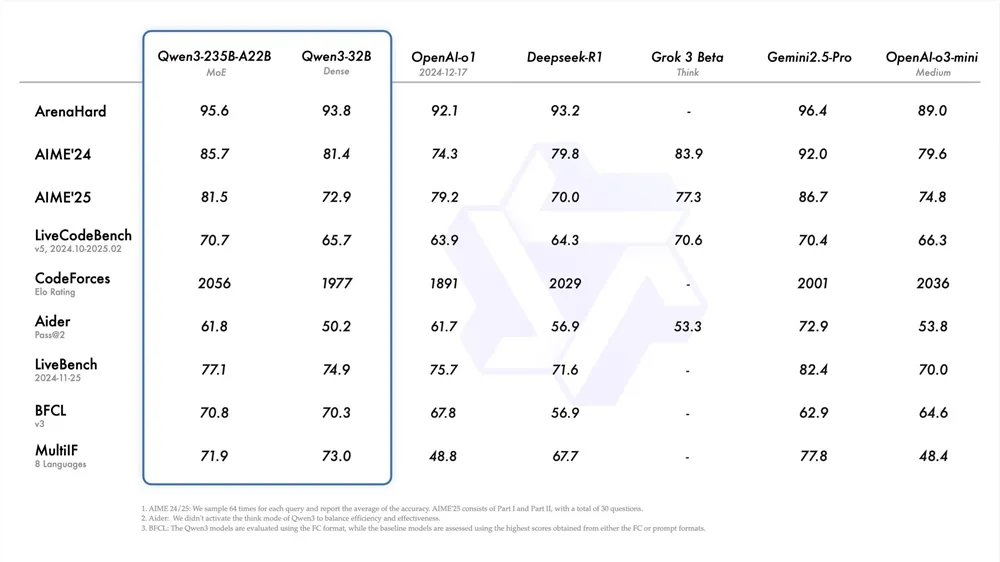
· 旗舰版235B-A22B(总参2350 亿,激活参220亿)仅需4张H20显卡就能本地部署,显存占用不到同类模型 1/3,编程、数学能力碾压 DeepSeek-R1、OpenAI o1;
· 平民版30B-A3B适配消费级显卡,激活参数仅 3B,性能却直逼 Qwen2.5-32B,中小开发者也能玩转 “混合专家”黑科技。
无论是个人做 AI 助手、企业搭智能客服,还是科研团队搞深度开发,Qwen3 都能精准匹配需求,真正实现 “开源不设限,人人用得起”。
“快思慢想” 双模式神了!
Qwen3 首创 “人类级思考引擎”,自带两种模式一键切换,彻底终结 “速度与精度” 的两难选择:
/no_think 快速模式
像闪电一样秒回答案,计算成本砍半,适合闲聊、查天气、客服等高频场景,吞吐量比 Qwen2.5 猛增 30%,再也不怕用户催 “快点回复”。
/think 深度模式
化身 “学霸大脑”,遇到数学题、代码调试等复杂任务,会像人类一样一步步拆解推理,甚至自我反思纠错,在 AIME’24 数学竞赛中准确率高达 85.7%,把一众国际大牌甩在身后

开发者通过简单指令就能自由切换,比如先用快速模式 “接住” 用户提问,再用深度模式 “精准解题”,一套模型搞定两种场景,部署成本直接腰斩!
Agent开发进入 “快车道”
原生支持 MCP 协议,AI从 “聊天”进化到“干活”
Qwen3野心远不止于 “更强的模型”,而要做“AI 生产力革命”的基础设施:
· 内置 MCP 协议:打通模型与外部工具的任督二脉,能自动调用计算器算财报、通过 API 查实时数据、甚至操控软件生成报表,彻底摆脱 “模型只能动口不能动手” 的困境;
· Qwen-Agent 框架加持:开发者无需从头造轮子,直接基于 Qwen3 快速搭建智能体,比如能自动处理邮件、跨系统数据同步、执行 API 调用的办公助手,让 AI 从 “回答问题” 进化到 “解决问题”,真正落地企业刚需场景。
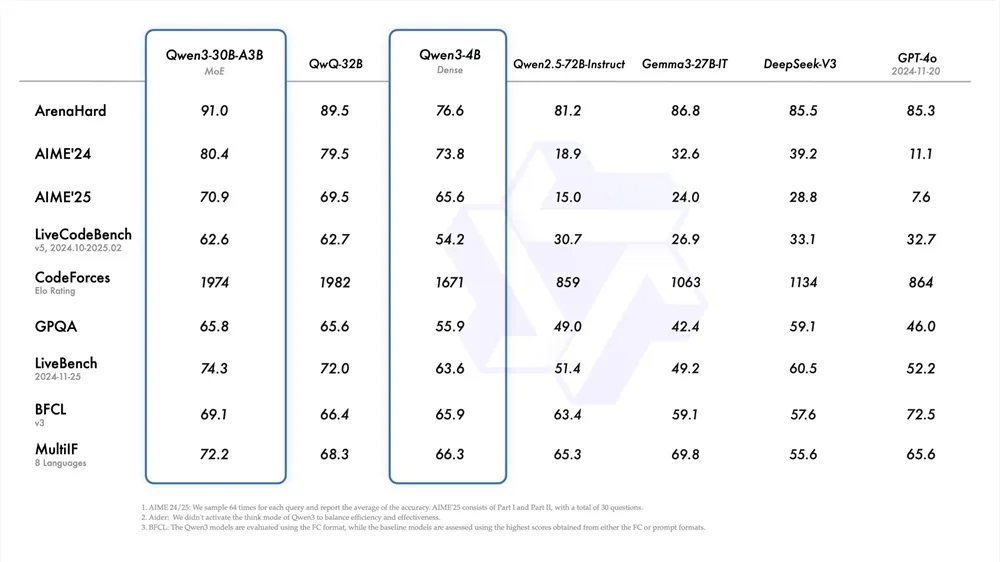
实测数据更惊艳
旗舰模型在CodeForces编程竞赛评分达2056,超越Grok-3和Gemini-2.5-Pro,代码生成、逻辑推理样样精通,妥妥的 “AI 打工人” 标配。
