深度实测!8卡H200在千亿MoE模型推理中的性能边界与优化策略
当整个AI行业为英伟达H200 GPU争抢破头,它已成为衡量企业AI实力的“硬通货”。

但它的真实性能边界究竟在哪?在高并发推理场景中,能否扛住千亿级大模型的极限压力?
我们直接上硬核实测:在一台搭载8张H200的服务器上,部署阶跃星辰最新多模态推理模型Step3——这是一款MoE架构的千亿级模型,总参数高达3210亿(321B),它采用混合专家设计,每次推理仅激活38亿参数(38B),包含48个专家层,其中激活3个专家+1个共享专家,最大上下文达65536 token。
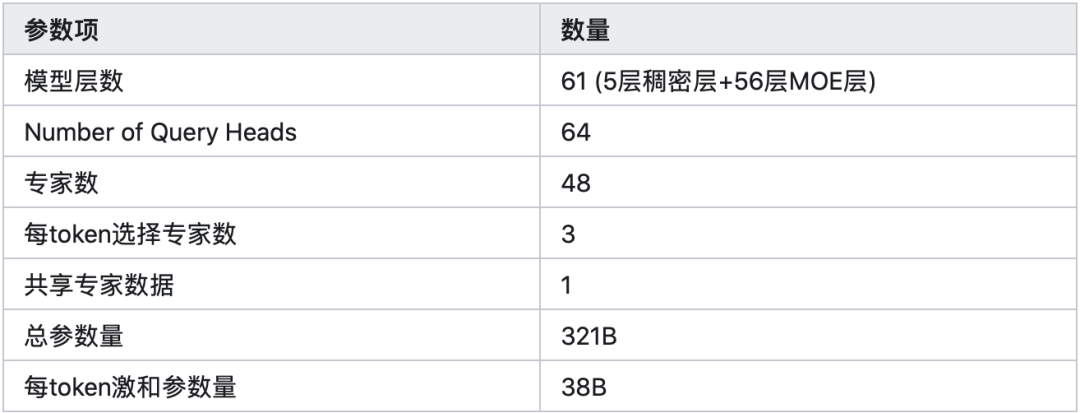
这种架构对显存容量和带宽提出了极高要求,也正是H200的用武之地。
“
测试环境
01
硬件配置
8× NVIDIA H200 GPU 141GB HBM3e 显存/卡 4.8TB/s 显存带宽/卡 NVLink 4.0 互联,双向总带宽 900GB/s
01
软件环境
测试参数
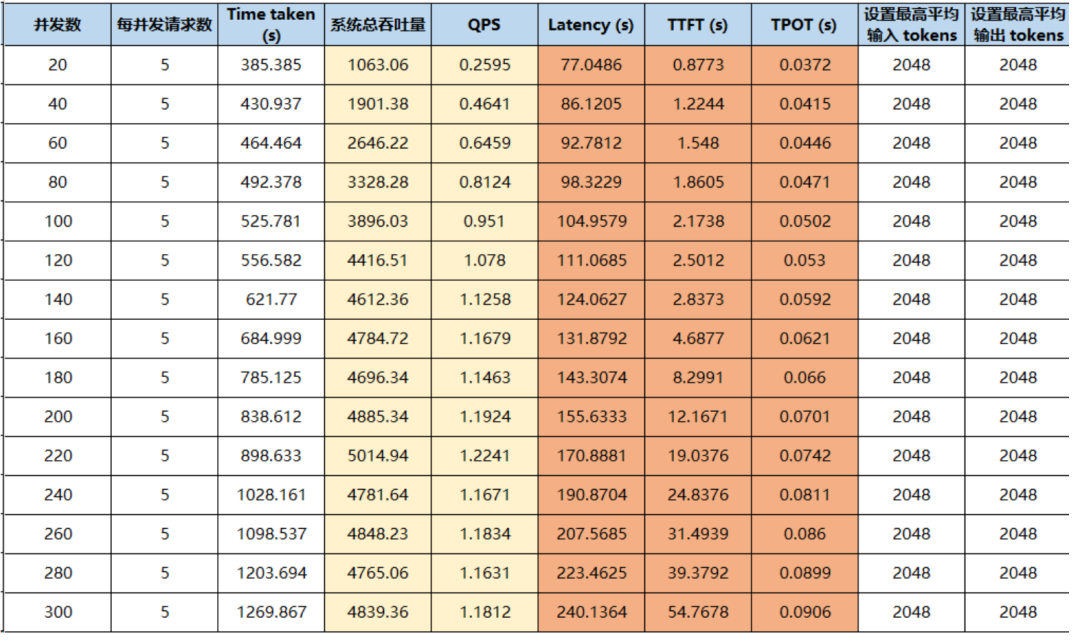
数据集:openga(对话类) 请求类型:OpenAI API兼容接口 输入长度:≤2048 tokens 输出长度:≤2048 tokens 并发数范围:20~300 总请求数:100~1500 每并发请求数:5
我们通过动态调整并发数,记录了首字延迟(TTFT)、吞吐量(token/s)及Token生成时间等关键指标,并将结果划分为三个典型区间:
· 高体验区(并发数<80)
当并发数低于80时,系统资源充裕,响应极速。实测数据显示
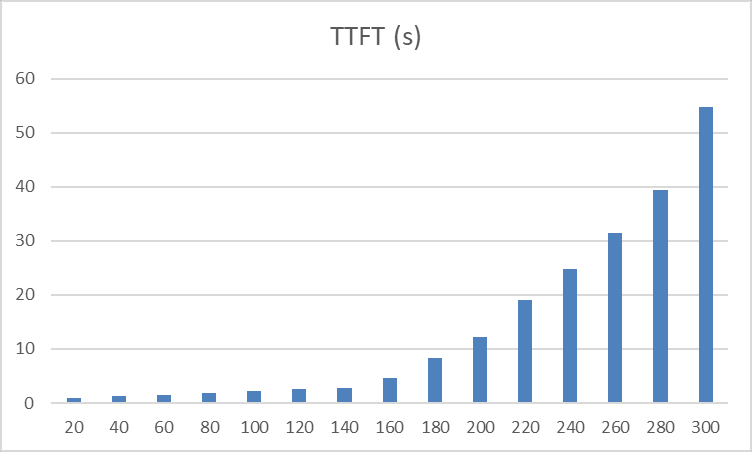
首字延迟(TTFT)低到可以忽略,用户对话几乎无卡顿;
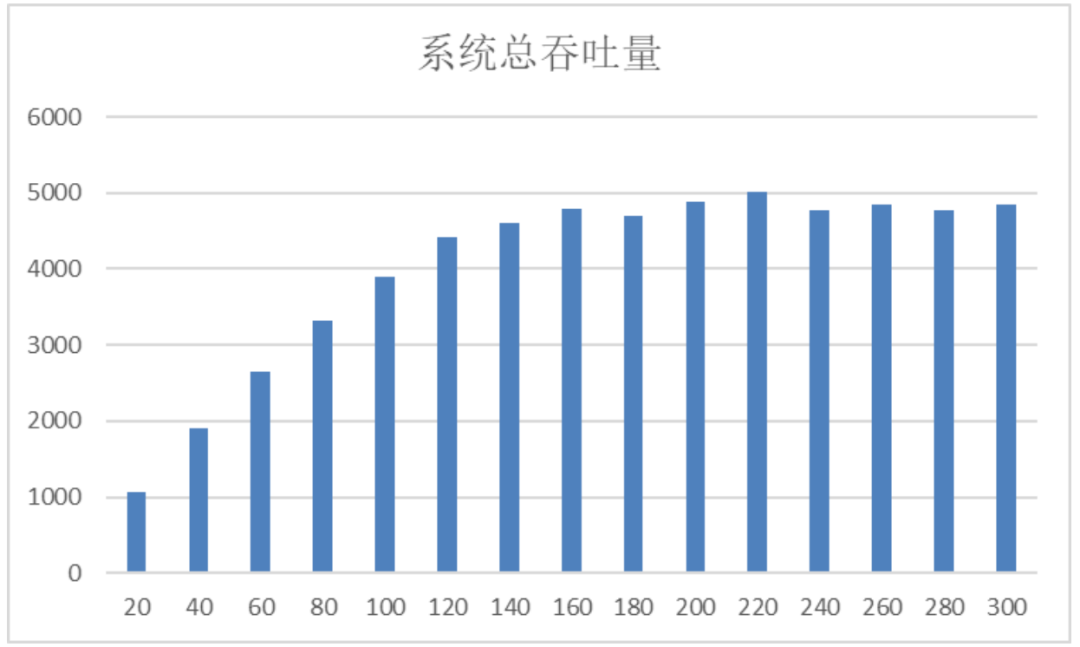
系统吞吐量随并发数线性增长,峰值直接突破5000 token/s;
Token生成时间稳定在60毫秒以内。
这一区间完美适配高端客服、实时对话助手等对交互体验要求极高的场景,让AI对话如丝般顺滑。
· 高吞吐区(并发数80~160)
随着并发数增加,系统进入最佳性价比区间:
系统吞吐量达到顶峰并稳定在5000 token/s以上,QPS接近极限;
首字延迟虽有明显增长,但整体仍在可接受范围。
这是性价比最高的区间,无需追加硬件投资,即可高效处理大规模批量任务,非常适合内容审核、智能推荐、离线批量推理等场景,实现效能最大化。
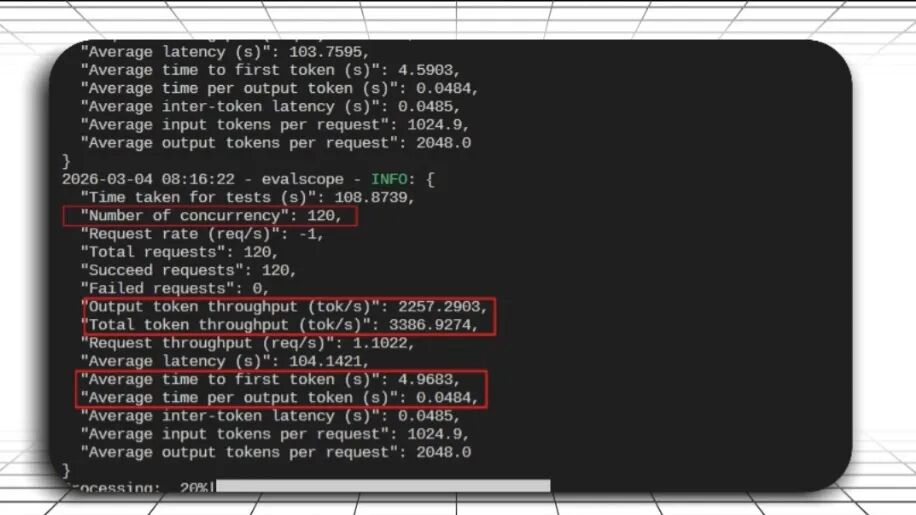
性能瓶颈区(并发数≥160)
吞吐量开始下降,首字延迟呈指数级飙升,请求排队严重。
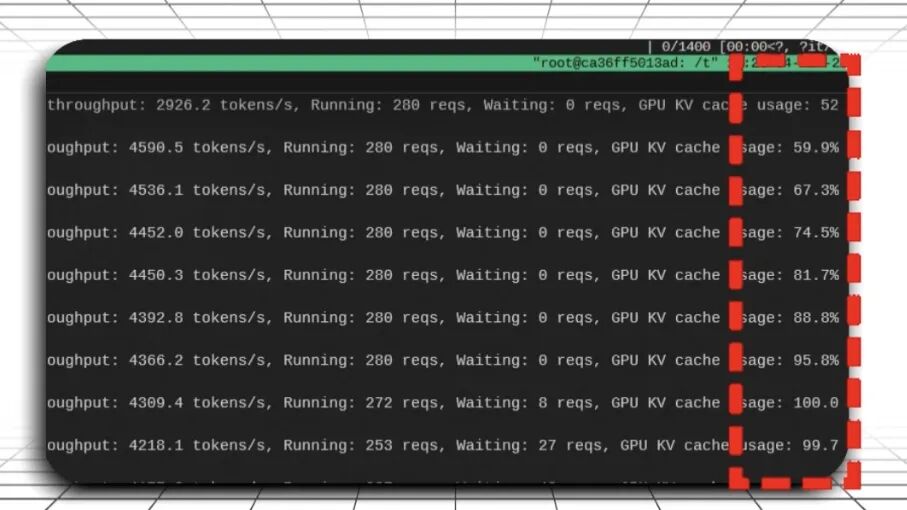
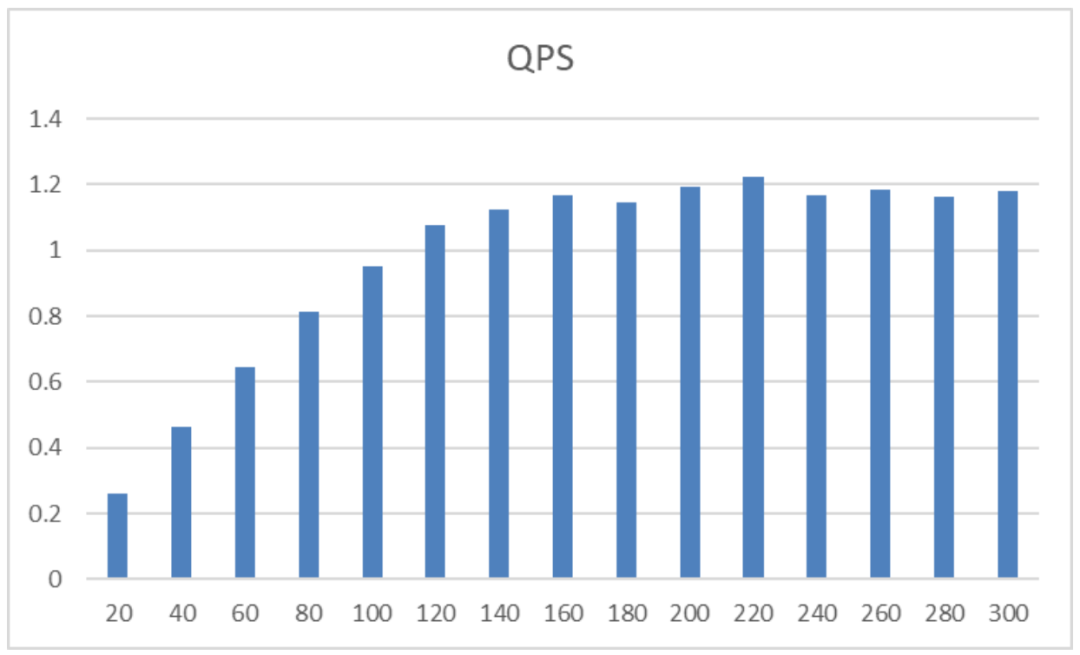
160并发即为当前8卡H200配置下的服务上限。超出此阈值,需通过扩容或负载均衡来缓解压力。
“
深度洞察:MoE架构的权衡
本次测试也揭示了MoE混合专家模型的独特优势:仅激活3个专家+1个共享专家,用较低的计算成本,使得模型的吞吐量和推理延迟得到极大的提升。
这也给企业带来启示:硬件选型须与模型特性深度匹配,盲目追求大参数模型,若无法有效利用稀疏激活特性,反而可能造成资源浪费。
Step3与H200的组合,正是“算法+硬件”协同优化的典范。

“
不止于硬件,更是全栈服务能力
拥有稀缺的H200 GPU,只是AI推理服务的起点。真正的核心竞争力,在于如何将硬件性能转化为稳定、高可用的商业服务——这正是点动科技的核心优势。
我们交付的从来不是单纯的服务器,而是全栈式服务能力:从模型适配、性能调优,到弹性伸缩、运维监控,为客户提供开箱即用的AI推理解决方案。
