国产大模型第一次!智谱GLM-4.7登顶Artificial Analysis全球开源榜首,代码能力碾压GPT-5.2
68 分综合成绩、开源第一、国产第一、全球第六,这份 2025 年终成绩单,智谱用 10 天写完。

“
2024 年以来,大模型行业的竞争逻辑正在发生变化。
如果说前两年,行业关注的核心仍集中在参数规模、训练数据量以及单点 benchmark 成绩,那么进入 2025 年,一个更现实的问题逐渐浮出水面:
大模型,是否真的具备进入真实生产环境的能力?
在这一背景下,智谱 AI 发布的 GLM-4.7,以“登顶全球开源模型榜首”的成绩,进入了行业视野的中心。相比高调发布参数或营销话术,GLM-4.7 的突破,更像是一次来自工程与应用侧的“反向证明”。
国产大模型,正在以不同于以往的方式,重新参与全球 AI 竞争。
“
榜单刷新的那条推文,让整个开源社区过年了

12月29 日凌晨,Artificial Analysis Intelligence Index(AA 智能指数)更新:智谱 GLM-4.7 以 68 分综合成绩,同时拿下「开源模型」与「国产模型」双料第一,全球总榜第六。这是国产大模型第一次在该榜单登顶,也是 2025 年最后一个工作日,中国 AI 给世界的彩蛋 。
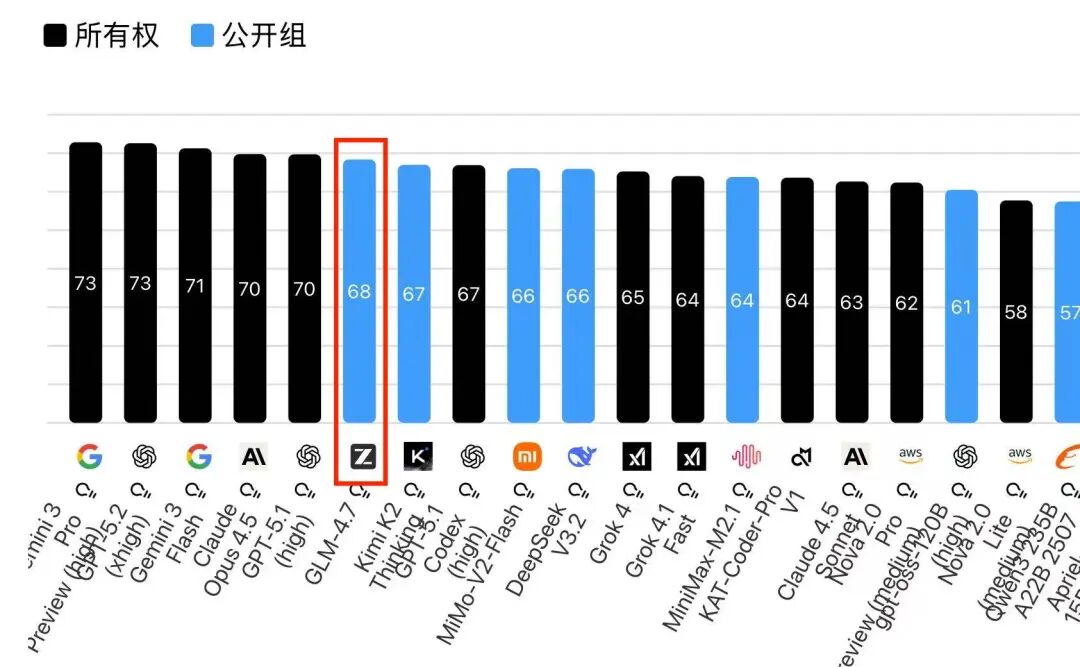
全球开源榜首背后:评价标准正在发生改变
AA 智能指数被业内称为“最挑剔的模型风向标”——不只看参数量,而是把知识储备、逻辑推理、代码生成、Agent 等硬核维度拉满。
GLM-4.7 能在里面夺魁,相当于在“铁人四项”里赢了全世界的开源选手。

“榜首”并不罕见,但 “全球开源模型榜首” 的意义,远高于常规榜单。
原因在于,开源模型的评价体系,本身更加贴近真实世界:
• 模型参数、结构、能力完全公开
• 评测结果可以被社区复现
• 性能不仅依赖一次性展示,而要经得起真实部署和开发者使用
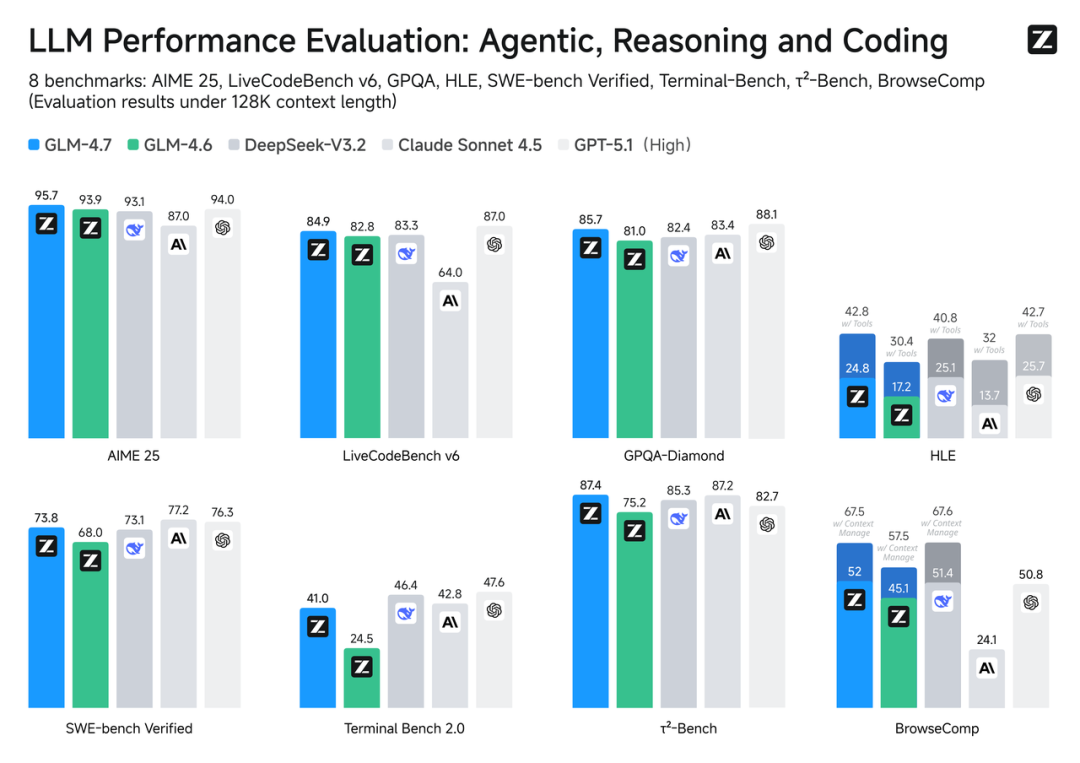
在这一语境下,GLM-4.7 的领先,并不只是“跑分更高”,而是意味着其在可用性、稳定性与工程完整度方面,达到了当前开源模型的第一梯队。
这也折射出一个更大的趋势:
AI 模型的价值评判,正在从“能力上限”转向“工程下限”。
为什么代码能力成了 2025 的“胜负手”?
过去一年,大模型从“会说”进化到“会做”。谁能一次生成可运行、可交付、可上线的代码,谁就能拿到通往 AI Native 世界的船票。
GLM-4.7 交出的答卷是
Code Arena 百万用户盲测:开源第一,力压 GPT-5.2
SWE-bench-Verified:73.8%,开源 SOTA,较上一代再涨 5.8%
LiveCodeBench V6:84.9 分,刷新开源纪录,超 Claude Sonnet 4.5
τ²-Bench 工具调用:87.4 分,开源第一,比 Claude Sonnet 4.5 还高
单枪匹马就能复刻植物大战僵尸、水果忍者——GLM-4.7 把“写代码”直接升级成“开游戏工作室”。

官网demo中由 GLM-4.7 独立完成的高交互小游戏,如植物大战僵尸、水果忍者。
一眼看懂 UI 稿,配色、布局、组件一次到位——GLM-4.7 让前端告别“像素级微调”,把审美写进第一行代码。

官网demo中GLM-4.7 增强了对视觉代码的理解。
16:9 PPT 即开即用,海报随手出片——GLM-4.7 让办公创作从“拼模板”进化到“拿设计奖”。

官网demo中GLM-4.7 在办公创作中版式与审美显著升级,PPT 16:9 适配率从52%跃升至 91%。
一句话总结:写代码、调 API、修 Bug、做前端,GLM-4.7 已经能“一条龙”端到端交付。
“先思考,再动手”GLM-4.7 的 3 种思考模式
智谱把“思维链”做成了可开关、可缓存、可轮级控制的“三件套”:
1. 交错式思考:每次回答前都过一遍脑子,复杂指令不跑偏
2. 保留式思考:多轮对话自动缓存思考块,长任务成本直降 30%+
3. 轮级思考:简单任务秒回,复杂任务开“深度思考”,时延与效果可兼得
在 Claude Code、TRAE、Cline、Roo Code 等主流框架里,GLM-4.7 默认支持“思考模式”,真正做到了“让模型先写伪代码,再写真代码”。
价格腰斩,速度拉满--国产算力红利来了

GLM-4.7 同步上线 BigModel.cn,API 定价只有 Claude 3.5 的 1/10;在昇腾、沐曦等国产芯片上推理延迟 < 50ms,成本再降 40% 。
对于想把钱花在算力而不是品牌上的开发者,这是 2025 年最友好的开源模型,没有之一。
“
智谱团队被 Reddit 网友提问
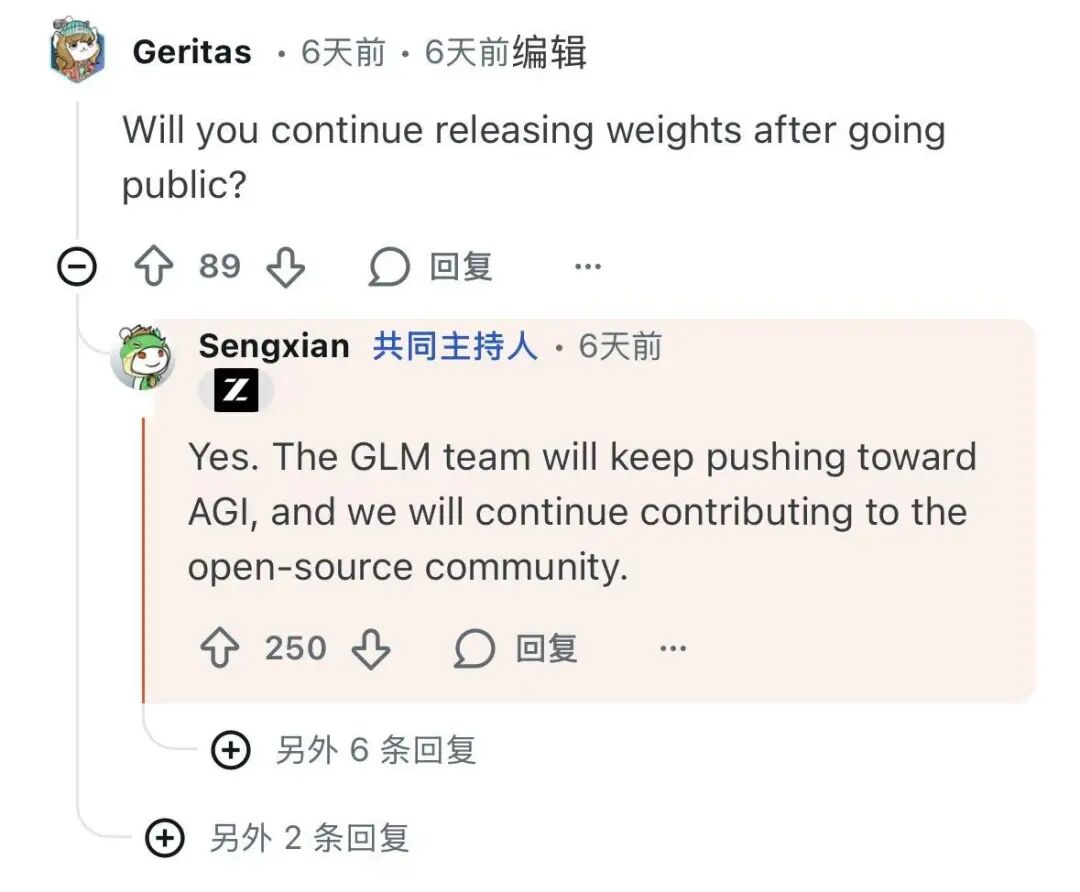
AMA 高赞提问:“上市后还会继续发布重量级产品吗”
答:“是的。GLM团队将继续推进AGI的发展,并继续为开源社区做贡献”
GLM-4.7 登顶全球开源榜首,并非孤立事件,而是 AI 行业从“技术竞赛”转向“产业落地竞赛”的缩影。
未来几年,大模型竞争或将呈现三大趋势:
工程化能力将成为企业竞争的核心分水岭;
开源生态的构建价值与协同效应将被重新评估;
多极化的全球 AI 竞争格局将逐步形成。
未来,模型是否“最强”,不再由实验室的基准测试定义,而是由真实产业场景的落地效果与价值创造能力决定。
“
写在最后

2025 年即将结束,国产大模型用实力把“开源”二字写进了全球 AI 的年终榜。
GLM-4.7 的登顶不是终点,而是中国 AI 真正走进“人人可落地、行行可编码”的起点。
新的一年,
愿我们都能用母语写出世界级产品,
Happy Coding,Happy 2026!
附:一键体验入口
- 模型:https://modelscope.cn/models/ZhipuAI/GLM-4.7
- 在线玩:https://z.ai
- API:https://bigmodel.cn
- GitHub:https://github.com/zai-org/GLM-4.5
部分素材来自互联网,侵权删
