OpenClaw 生产级必看:A6000 vs 4090 长文本推理实测,高并发吞吐量谁是王者?
OpenClaw 正成为企业级智能体与自动化工作流的标准框架,在文档解析、知识库问答、长文本提取、流程自动化等场景快速落地。
但几乎所有团队在推向生产时,都会遇到同一个致命瓶颈:让 OpenClaw 处理几万字长文档 → 输出精简结论这类高输入低输出任务时,响应不稳定、高峰期延迟飙升、并发上不去、算力成本失控。
问题不在模型,不在框架,而在于:硬件选型与推理负载不匹配。
长文本推理是一种极不对称负载:
· KV Cache 占用极高
· 显存压力远大于计算压力
· 对并发调度、精度策略、显存容量敏感
· 与普通对话模型的硬件需求完全不同
为了让企业不再盲目选卡、不再靠经验踩坑,点动科技利用自有双8卡标准服务器集群环境,对 A6000 与 RTX 4090 进行生产级压力实测。
本次测试核心目的在于,揭开 OpenClaw 长文本推理的性能底层逻辑,明确显存、精度、模型规模如何共同决定并发与吞吐量,给出不同业务场景下最优硬件选型,提供可直接落地的“成本&性能”最优解。

“
测试环境
1
硬件配置
A6000×8(48GB显存/卡)VS 4090×8(24GB显存/卡)
2
软件配置
操作系统:Ubuntu24.04+最新版本Docker
GPU驱动:NVIDIA Driver580
CUDA版本:13.0
推理引擎:vLLM v0.18.0
3
负载模型
并发数:60
单并发循环请求:5次
单请求输入:30000Tokens(超长文本)
单请求输出限制:300Tokens(短结论输出)
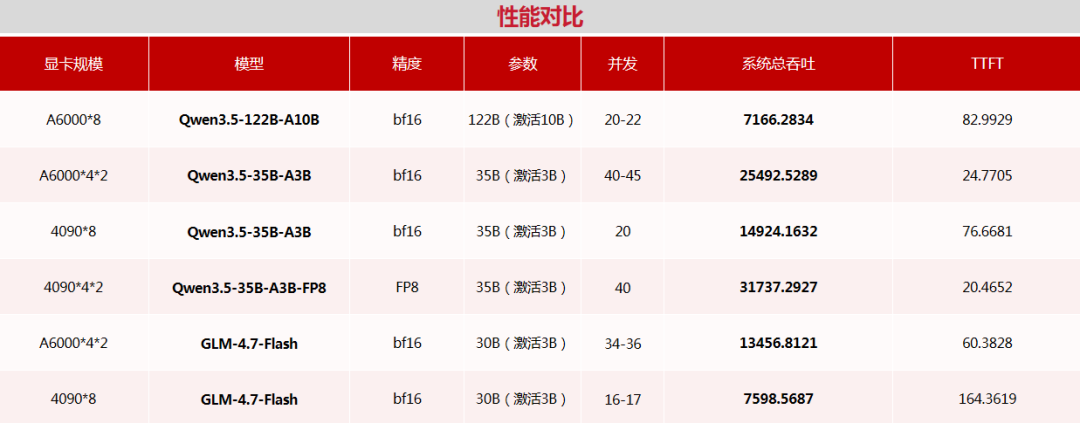
首先,显存决定大模型上限。在企业最常用的 BF16 原生精度下,A6000可直接加载 Qwen3.5-122B-A10B,吞吐7166.28 Token/s,稳定并发20~22,4090仅支持最大约75B模型,122B模型无法运行。
· 关键结论:BF16 精度下,模型参数超 75B条件下,A6000是最优解
同精度下对比Qwen3.5-35B-A3B BF16的表现,A6000总吞吐25492.5289 Token/s,稳定并发40~45,TTFT为24.77ms;4090总吞吐14924.1632 Token/s,稳定并发20,TTFT为76.67ms。A6000 吞吐量领先约 70%,并发能力翻倍,Token 延迟低至 1/3。
· GLM-4.7-Flash测试验证:A6000显存带来的并发优势跨模型通用
精度选择是关键变量,A6000架构不支持FP8,而4090原生支持。用Qwen3.5-35B-A3B-FP8,4090总吞吐达到31737.2927Token/s,为本次测试最高值,稳定并发提升至40,TTFT进一步降至20.47ms。
· 模型支持 FP8 时:4090 效率、延迟、吞吐量全面超越 A6000
GLM-4.7-Flash的测试结果进一步确认了这个规律:BF16精度下模型不同,但A6000在BF16精度下的优势没有变。这说明显存容量带来的并发承载能力提升,是跨模型普适的,而非某一特定模型的优化结果。

关键结论:OpenClaw 长文本推理的三大铁律
· 显存容量决定了BF16 场景并发天花板:显存越大能承载的并发越高、模型越大
· 精度策略是性能放大器:BF16 靠显存。FP8 靠架构。选型先定精度。
· 没有最优卡只有最优配置:模型大小、精度、并发、输入长度四项共同决定硬件
直接抄作业:OpenClaw 硬件选型指南
· BF16 精度、模型>75B:必选 A6000,4090 无法加载
· 35B 级 BF16、低并发<20:4090成本更优,A6000吞吐量更高
· 35B 级 FP8、高并发:4090 性能最强,性价比拉满
· GLM-4.7-Flash 等高并发长文本任务: A6000 更稳定、并发余量更大

点动科技在粤港澳大湾区已部署超6000P推理算力集群,全覆盖H200、L40、A6000、4090等企业级GPU,提供从硬件环境、模型适配、性能调优到高并发稳定运行的全栈式推理服务。企业无需自建机房、反复试错,接入即可跑生产。
我们采用灵活 Token 计费模式,真正贴合企业使用习惯:
· 按需消耗:独立结算,不为闲置算力买单;
· 项目验证期:零预付、低成本、无浪费;
· 规模化上线:用量越大单价越低,长期使用成本更省;
全周期支出清晰可查,实现算力成本精细化管理。让 OpenClaw 在长文本推理场景跑得稳、并发高、成本低,专注业务,不用操心硬件。
